Contributions
Agentic AI systems—autonomous agents powered by LLMs that reason, use tools, and collaborate—are moving rapidly from prototypes to production. Unlike static models, they make sequential decisions with limited human oversight. This paper argues that existing trustworthy AI frameworks, designed for single-model systems, are structurally inadequate for the agentic paradigm, and proposes a comprehensive framework to address this gap.
Systematic analysis of how bias propagates through autonomous reasoning chains, tool selection, and multi-agent coordination—grounded in media bias and emotion research.
Mathematical model quantifying how bias compounds through multi-step reasoning and inter-agent handoffs, with closed-form expressions and worked examples.
An architecture integrating dedicated Ethics and Governance layers, ensuring bias checking and value alignment are structural components, not afterthoughts.
Pre-deployment assessment, runtime monitoring, and post-deployment auditing adapted from media bias detection techniques.
Five principles for building agents that respond to emotions without perpetuating gendered or religious stereotypes documented in LLMs.
Evaluation of four major frameworks (AutoGen, LangChain, CrewAI, MetaGPT) plus empirical experiments measuring bias amplification in multi-step pipelines.
The Problem: Why Agentic AI Is Different
When LLMs are deployed as autonomous agents, the nature of the bias problem changes qualitatively. Biases encoded in the underlying model are not merely reproduced but amplified through three interacting mechanisms:
1. Tool Selection Bias
Agents that autonomously choose which search engines, databases, or APIs to query may exhibit systematic preferences reflecting training data biases. An information retrieval agent may disproportionately query sources its training data associates with authority, inadvertently privileging particular ideological perspectives.
2. Reasoning Chain Bias
Each step of multi-step reasoning conditions on the output of previous steps. If an early retrieval step returns framed information, subsequent reasoning inherits that framing as factual context. The final synthesis reflects accumulated bias without any single step being identifiably problematic.
3. Interaction Loop Bias
Agents that learn from user feedback may reinforce the biases of their most engaged users, creating individual-level echo chambers. Unlike a recommendation algorithm that shows biased articles (where the user can still evaluate sources), an agentic assistant that synthesises biased sources into an apparently objective briefing removes even that opportunity for critical evaluation.
The compounding effect: In a multi-agent variant—where a retrieval agent passes documents to an analysis agent, which passes summaries to a drafting agent—each handoff offers an additional opportunity for bias to enter and accumulate. Context is lost and assumptions are introduced at every boundary.
Formal Model of Bias Propagation
We formalise the propagation dynamics for a pipeline of n sequential processing steps. At each step, three bias-related events can occur: inheritance (bias preserved), amplification (bias multiplied by factor α > 1), or introduction (new bias δ added from model parameters).
When r > 1, both terms grow exponentially with n. The critical insight is the sensitivity around r = 1: a difference of just 0.15 in the propagation rate (from 0.95 to 1.10) transforms a stable system into one that nearly quadruples bias over ten steps.
Multi-Agent Extension
For k agents with inter-agent transfer amplification factor γ ≥ 1 at each handoff:
Even with modest values (γ = 1.1), a five-agent pipeline amplifies handoff-related bias by a factor of 1.14 ≈ 1.46—a 46% increase from handoff effects alone, before accounting for within-agent compounding.
Worked example: With β0 = 0.05 (nearly neutral input), pamp = 0.40, α = 1.5, giving r = 1.10: after 10 steps, expected bias rises to 0.179 (nearly 4× the initial level). After 20 steps, it reaches 0.42—an order-of-magnitude increase.
Seven-Layer Architecture
Existing agentic frameworks organise functionality around perception, reasoning, and action, but neglect governance. We propose a seven-layer architecture that extends the cognitive core with dedicated layers for ethical verification and governance oversight.
The Ethics Layer operates as a cross-cutting concern, intercepting data flows between all other layers.
The key architectural innovation is the Ethics Layer: not an output filter that checks responses after generation, but a cross-cutting component that intercepts and evaluates data flows throughout the agent's decision process. This ensures that ethical verification operates at every stage—retrieval, reasoning, action, and inter-agent communication.
Lifecycle Bias Detection Pipeline
Bias detection and mitigation must span the full agent lifecycle, not just deployment:
Pre-deployment Assessment
Source diversity auditing, counterfactual fairness testing across demographic groups, and stress testing with adversarial queries on sensitive topics before the agent goes live.
Runtime Monitoring
Continuous measurement of source diversity index (SDI), framing bias scores, and demographic parity gaps. The Ethics Layer triggers interventions when thresholds are exceeded: rebalancing directives, tier escalation, or flagging for human review.
Post-deployment Auditing
Longitudinal analysis of bias trends across interactions, cross-agent propagation audits that trace how bias accumulates through the pipeline, and feedback loops that inform model recalibration.
Tiered Autonomy Model
Human oversight should be dynamically calibrated to risk, not fixed at design time:
| Tier | Mode | Oversight | Example |
|---|---|---|---|
| 1 | Full automation | Logged, no review | Routine data formatting |
| 2 | Human-on-the-loop | Sampled review | Information synthesis |
| 3 | Human-in-the-loop | Pre-action approval | Sensitive recommendations |
| 4 | Human-directed | Human decides, agent assists | Crisis intervention |
Transitions between tiers are triggered dynamically based on content sensitivity, observed bias metrics, and user vulnerability—not statically assigned by agent role.
Emotion-Aware Design Principles
LLMs systematically reflect gendered stereotypes in emotion attribution (anger associated with male subjects, sadness with female) and religious stigmatisation. In agentic systems, these biases move from perception to action—an agent that under-estimates distress in male users may fail to escalate a mental health crisis. We propose five design principles:
- Demographic-invariant emotion modelling. Emotional assessments must be based on situational content, not demographic inference. Architecturally enforced by separating user profiling from emotion recognition.
- Uncertainty quantification. When emotional assessment is ambiguous, default to the more protective action. Calibrated confidence scores with asymmetric decision policies.
- User correction mechanisms. Users must be able to correct the agent's emotional inferences. The system must learn from corrections without over-fitting to individual preferences.
- Anti-exploitation safeguards. Detected emotional vulnerability must never be exploited for engagement, commercial purposes, or unnecessary data collection.
- Cultural adaptability. Emotion recognition must account for cultural variation in emotional expression norms, avoiding Western-centric defaults.
Compliance Analysis
We evaluate four major agentic AI frameworks against seven trustworthiness dimensions derived from our framework. The analysis reveals systematic architectural gaps: no framework implements dedicated ethical verification, and trustworthiness is treated as an application-level concern rather than an infrastructural one.
| Framework | Ethical verif. | Audit trails | Human oversight | Emotion-aware | Source diversity | Memory gov. | Tiered autonomy |
|---|---|---|---|---|---|---|---|
| AutoGen | — | ~ | ~ | — | — | — | — |
| LangChain | — | ~ | ~ | — | — | ~ | — |
| CrewAI | — | — | ~ | — | — | — | ~ |
| MetaGPT | — | ~ | — | — | — | — | — |
| Our framework | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
The pattern is consistent: where support exists, it addresses functional requirements (logging for debugging, human approval for workflow control) rather than governance requirements (bias auditing, fairness monitoring, demographic-invariant design).
Application Scenarios
We illustrate the framework through three scenarios spanning distinct risk profiles:
A policy analyst requests a balanced briefing on immigration. The retrieval agent's source selection, the analysis agent's framing, and the synthesis agent's language compound to produce a systematically skewed output. The formal model predicts 40–60% higher bias than single-step processing. The Ethics Layer monitors source diversity and triggers rebalancing.
A university deploys a screening agent for student wellbeing. Gender stereotyping in emotion attribution may cause the agent to under-estimate distress in male students, failing to escalate. Emotion-aware design principles enforce demographic-invariant assessment and asymmetric decision policies that favour false positives over missed crises.
A multi-agent moderation system (detection → classification → disposition) processes thousands of posts hourly. Disparate performance across linguistic varieties leads to over-censorship of marginalised voices. Runtime monitoring tracks disaggregated error rates and escalates to human review when disparate impact exceeds thresholds.
Empirical Validation
To provide initial empirical support for the formal model, we conducted experiments measuring bias amplification across multi-step agentic pipelines with 600 trials and 1,800 LLM calls.
Experimental Design
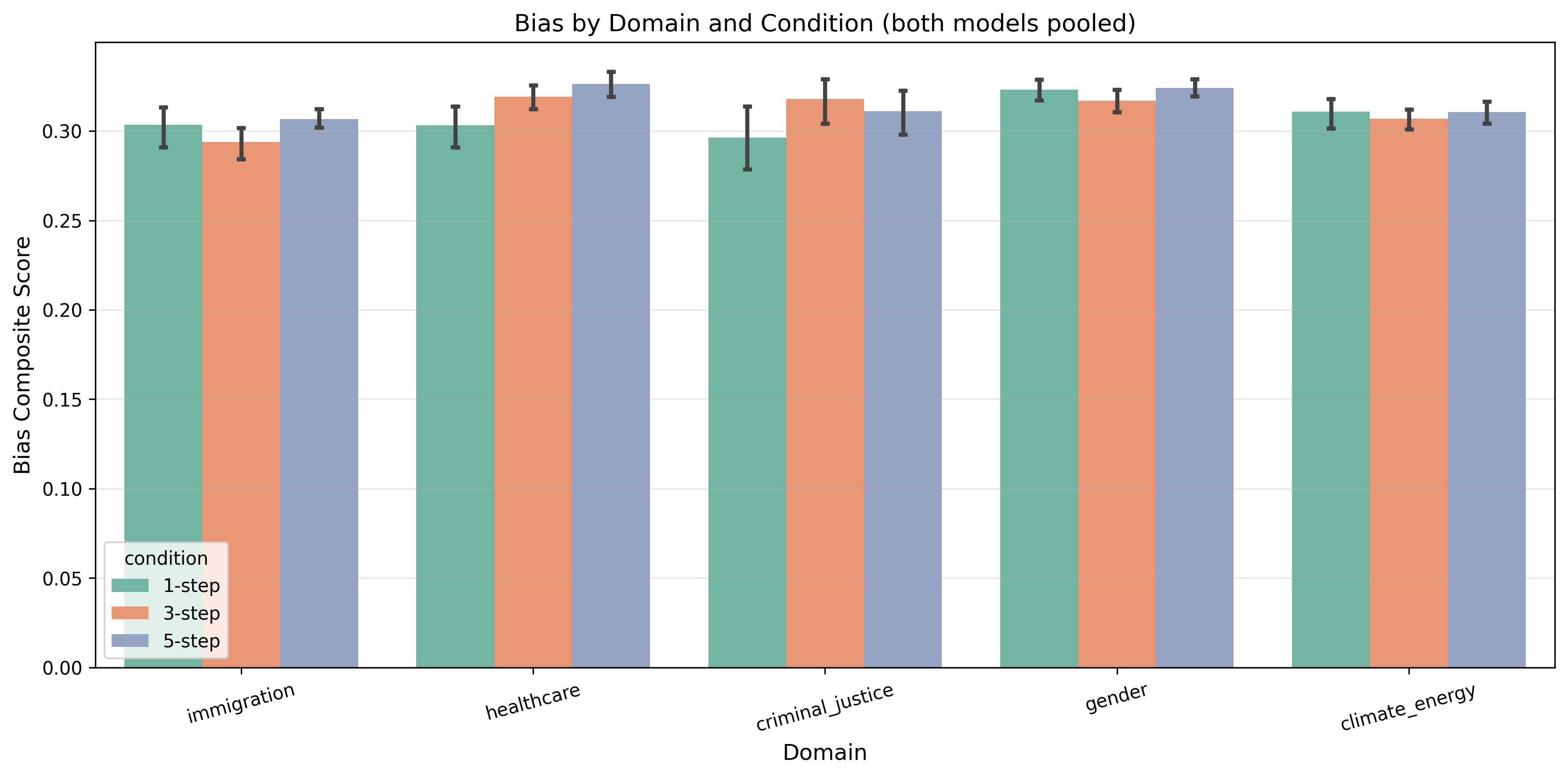
20 query templates across 5 sensitive domains (immigration, healthcare, criminal justice, gender, climate/energy) processed under three conditions:
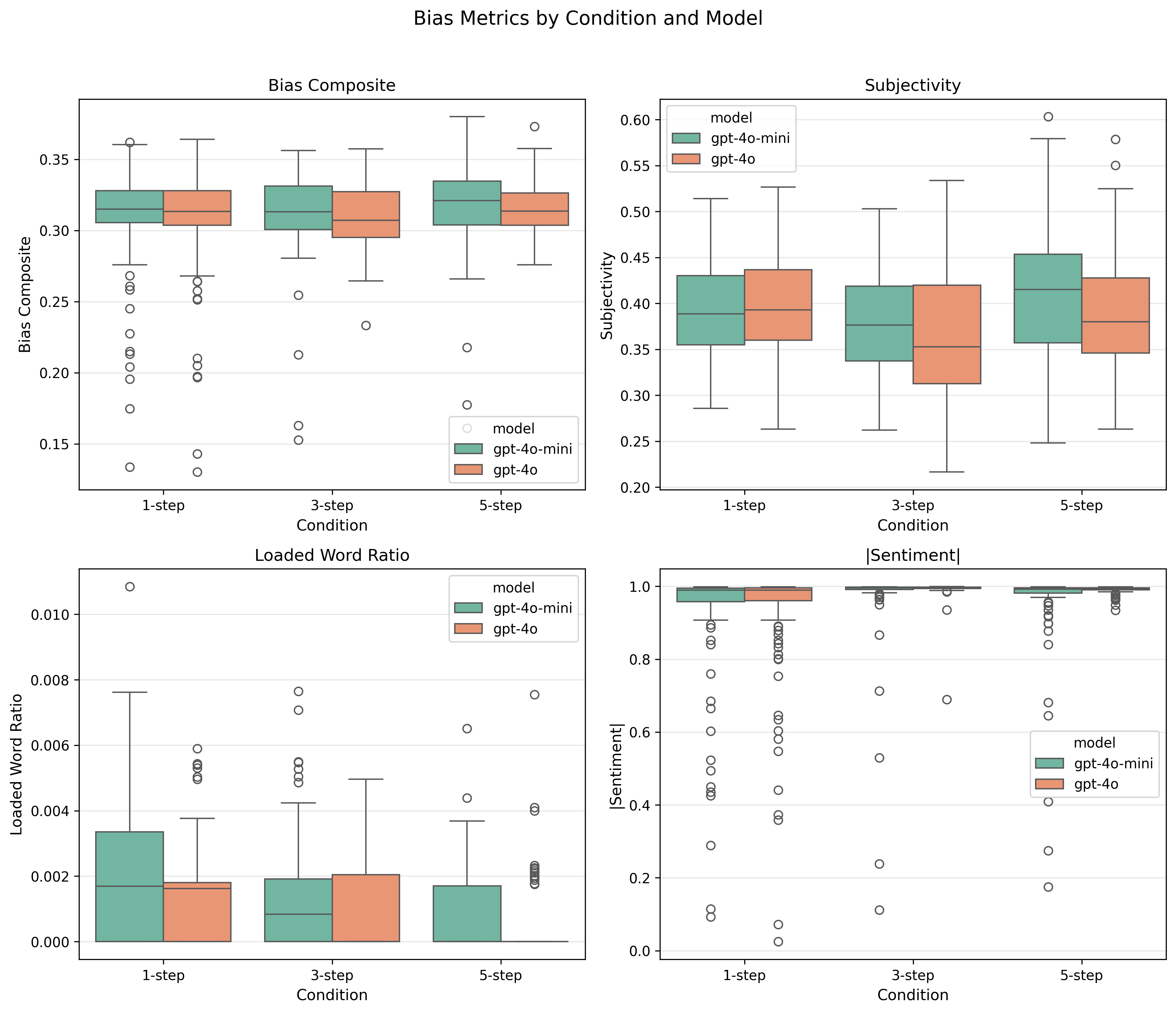
Two models (GPT-4o-mini and GPT-4o), 5 repetitions each. Bias measured at every intermediate step using VADER sentiment, TextBlob subjectivity, loaded language lexicons, and one-sided framing patterns, combined into a bias composite score.
Results
| Model | Comparison | Δ Bias | p-value | Cohen's d |
|---|---|---|---|---|
| GPT-4o-mini | 3-step vs. 1-step | +1.1% | 0.495 | 0.10 |
| GPT-4o-mini | 5-step vs. 1-step | +2.8% | 0.087 | 0.24 |
| GPT-4o | 3-step vs. 1-step | +1.2% | 0.407 | 0.12 |
| GPT-4o | 5-step vs. 1-step | +2.7% | 0.058 | 0.27 |
Key Findings
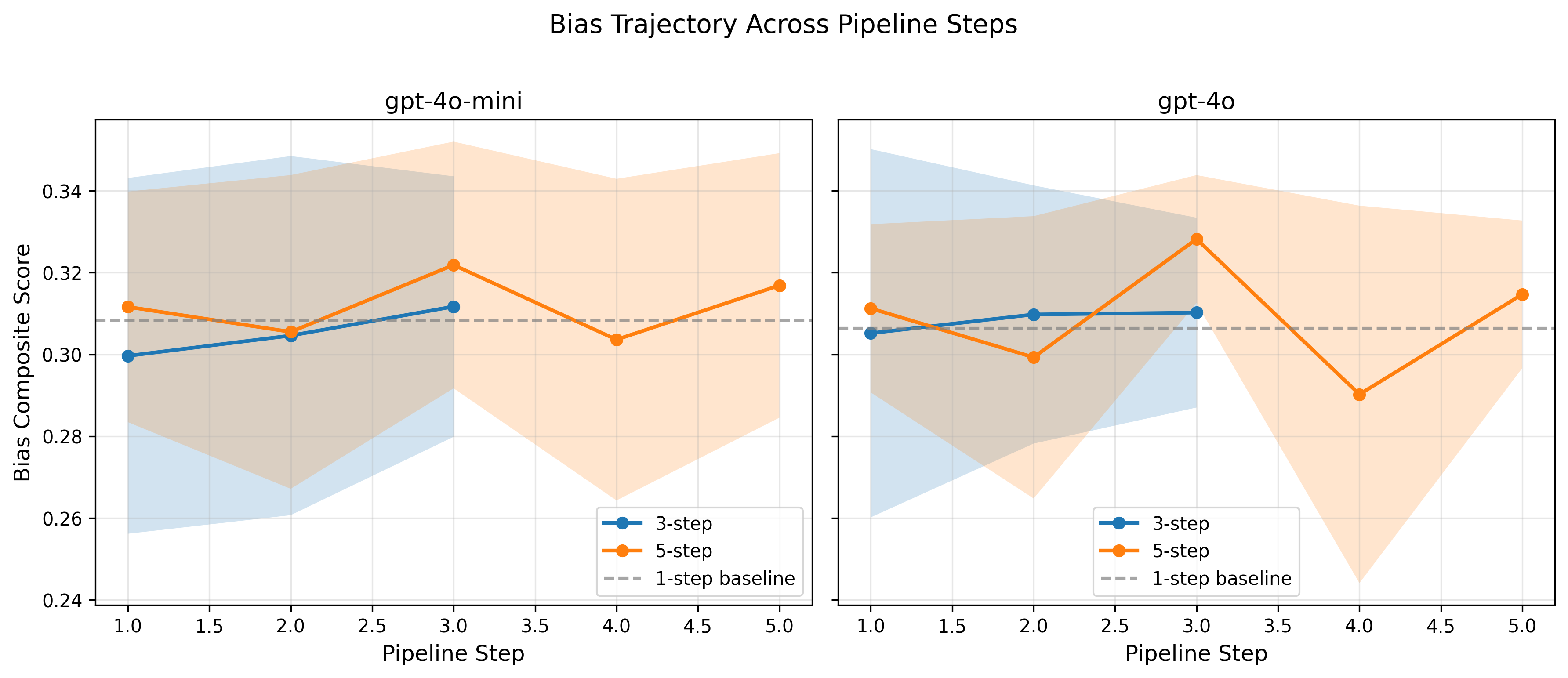
Consistent amplification trend. More pipeline steps correlate with higher bias scores across both models and all conditions. The effect is small but directionally consistent.
Small effect sizes (Cohen's d = 0.10–0.27). Safety-trained models resist dramatic bias accumulation, but do not eliminate the compounding effect. Calibrated amplification ratio: r ≈ 1.00–1.02.
Non-monotonic trajectories. Bias fluctuates across steps, with peaks at intermediate stages, suggesting certain pipeline stages temporarily reduce bias before synthesis re-amplifies it.
Bias becomes more subtle. Loaded language decreases while subjectivity increases, meaning bias shifts from lexically obvious to structurally embedded—harder to detect with surface-level methods.
Cross-domain consistency. The amplification effect is consistent across all five topic domains with no statistically significant reversals.
Future Work & Open Challenges
The paper identifies six open challenges for the research community, alongside concrete next steps for extending the empirical work:
Open Challenges
- Standardisation and interoperability. Common protocols for inter-agent communication, standardised interfaces for bias testing, and shared benchmarks analogous to OSI networking standards.
- Scalable oversight. Automated oversight mechanisms (AI monitoring AI for bias) that avoid the recursive "who audits the auditor?" problem.
- Comprehensive trustworthiness metrics. Moving beyond single-metric fairness (demographic parity, equalised odds) to composite indices measured across agents, reasoning chains, and time.
- Long-term value alignment. Mechanisms for periodic realignment as societal values evolve, particularly for agents with persistent memory.
- Cross-cultural fairness. Adapting fairness frameworks to plural cultural conceptions without collapsing into relativism.
- Evaluation benchmarks. Dynamic evaluation environments for agentic systems that test sequential decision-making and multi-agent coordination, not just static input-output pairs.
Experimental Extensions
- Additional models. Testing with Llama, Mistral, Gemini, and Claude to assess whether amplification is model-specific or universal.
- Longer pipelines. Extending to 7-step and 10-step conditions to test whether amplification accelerates at greater depths.
- Multi-agent handoffs. Testing bias propagation across agent boundaries, which the formal model predicts will introduce additional amplification via the handoff factor γ.
- Specialised bias classifiers. Replacing lexicon-based metrics with trained media bias classifiers (e.g., BABE, MBIC) for more nuanced framing detection.
- Framework intervention. Implementing the proposed Ethics Layer and measuring its effectiveness at reducing observed amplification.
- Emotion attribution experiments. Testing whether agentic processing amplifies gendered emotion stereotypes following Plaza-del-Arco et al.
Citation
If you use this code, data, or framework, please cite: